



Minitab技術サポートで働いていたとき、お客様から「CpkとPpkの違いは何ですか?」とよく聞かれました。良い質問です。実務家の多くのがCpkを使用するときにPpkを完全に見落としているというのはお決まりの出来事だからです。CpkとPpkは1980年代の人気デュオ、ワム!のようなものです。Cpkはジョージ・マイケル、Ppkはもう一人です。
ムースで決めたかっこいいヘアスタイル、肩パッド、レッグウォーマーはさておき、まずは、合理的なサブグループを定義して、CpkとPpkの違いを調べてみましょう。
合理的なサブグループ
合理的なサブグループは、一組の同じ条件下で生成された測定値のグループです。サブグループは、工程の「スナップショット」を表すものです。したがって、サブグループを構成する測定値は、類似した時間から取られる必要があります。たとえば、1時間ごとに5つのアイテムをサンプリングする場合、サブグループサイズは5になります。
計算式、定義など
工程能力分析の目標は、工程が顧客仕様を満たせることを確認することで、その評価を行うために、CpkやPpkなどの工程能力統計量を使用します。正規(分布)工程能力のCpkとPpkの計算式を見ると、ほぼ同じであることがわかります。
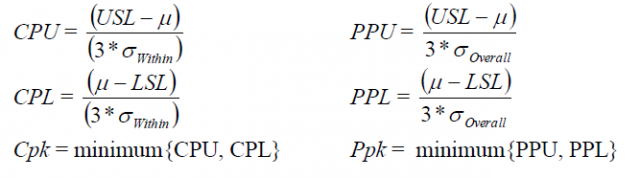
唯一の違いは、それぞれの式の分母です。CpkはσWithinを使用して計算され、PpkはσOverallを使用して計算されます。標準偏差の計算式に関する詳細はさておき、σWithinはサブグループ標準偏差の平均と考えてください。一方、σOverallはすべてのデータの変動を表します。これは次のことを意味します。
Cpk:
-
サブグループ内の変動のみを考慮に入れます
-
サブグループ間のシフトとドリフトは考慮に入れません
-
しばしば潜在的な工程能力とみなされます。これは、サブグループ間で変動(すなわち時間の経過)がないと仮定した場合、規定の範囲内で部品を製造する際に、その工程が持つ潜在能力を表すことになるからです。
Ppk:
-
得られたすべての測定値の全体の変動を考慮に入れます
-
理論上、サブグループ内の変動と、サブグループ間のシフトとドリフトの両方が含まれます
-
典型的な一日の平均値のようなものです
CpkとPpkの違いの例
イメージできるよう、10日間毎日5つの測定値が得られるデータセットについて考えてみましょう。
例1 - CpkとPpkが類似する
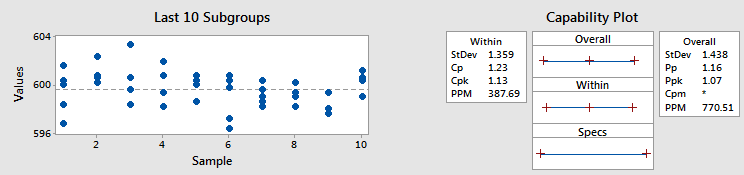
左側のグラフで示されるように、サブグループ内の変動と比べると、サブグループ間ではシフトとドリフトがあまり多くありません。したがって、Withinの標準偏差とOverallの標準偏差は類似しています。つまり、CpkとPpkも類似しています(それぞれ1.13と1.07)。
例2 - CpkとPpkが異なる
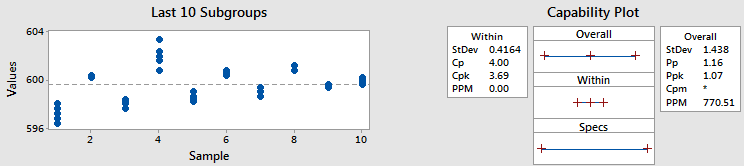
この例でも同じデータとサブグループサイズを使いましたが、データをシフトして別のサブグループに動かしました(もちろん実際にはデータを別のサブグループには動かすことはありませんが、今回は要点を説明するためにそうしました)。
同じデータを使ったため、overallの標準偏差とPpkは変わりませんでした。しかし類似点はこれだけです。
Cpk統計量を見てください。3.69です。前の1.13よりもはるかに良いです。サブグループのプロットを見て、Cpkが増加した理由がわかりますか?グラフ内で、各サブグループ内の点が先ほどよりもずっと密集しています。先ほど、σWithinはサブグループ標準偏差の平均と考えることができると述べました。それで、各サブグループ内の変動が少ないことは、σWithinの変動が小さいということになるのです。これによりCpkが高くなります。
Ppkにするべきか否か
ここで注意が必要です。ジョージ・マイケルの相方が誰だったかが忘れられることはあっても(悪気はありません)、Cpkを報告するだけでPpkを忘れてしまうということがあってはいけません。上の例から、Cpkは物語の一部しか伝えていないことがわかります。したがって、次に工程能力を調べるときは、CpkとPpkのどちらも考慮に入れてください。また、工程が安定し、時間の経過による変動がほぼない場合、2つの統計量はやはりほぼ同じはずです。
(注:サブグループサイズが1の場合などは特に、PpkがCpkよりも大きくなる場合があります。それは特に問題ありません。そのことは別の日に説明したいと思います。)