



By Peter Olejnik, guest blogger.
Previous posts on the Minitab Blog have discussed the work of the Six Sigma students at Rose-Hulman Institute of Technology to reduce the quantities of recyclables that wind up in the trash. Led by Dr. Diane Evans, these students continue to make an important impact on their community.
As with any Six Sigma process, the results of the work need to be evaluated. A simple two-sample T test could be performed, but it gives us a very limited amount of information – only whether there is a difference between the before and after improvement data. But what if we want to know if a certain item or factor affects the amount of recyclables disposed of? What if we wanted to know by how much of an effect important factors have? What if we want to create a predictive model that can estimate the weight of the recyclables without the use of a scale?
Sounds like a lot of work, right? But actually, with the use of regression analysis tools in Minitab Statistical Software, it's quite easy!
In this two-part blog post, I’ll share with you how my team used regression analysis to identify and model the factors that are important in making sure recyclables are handled appropriately.
Preparing Your Data for Regression Analysis
All the teams involved in this project collected a substantial amount of data. But some of this data is somewhat subjective. Also, this data has been recorded in a manner that is geared toward people, and not necessarily for analysis by computers. To start doing analysis in Minitab, all of our data points need to be quantifiable and in long format.
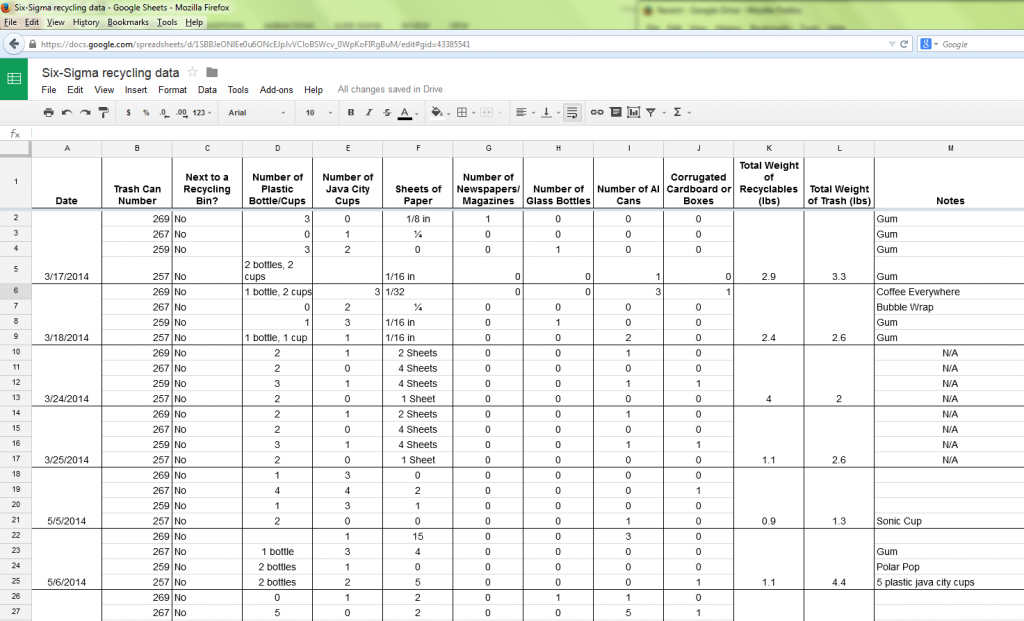
The Data as Inserted by the Six Sigma Teams
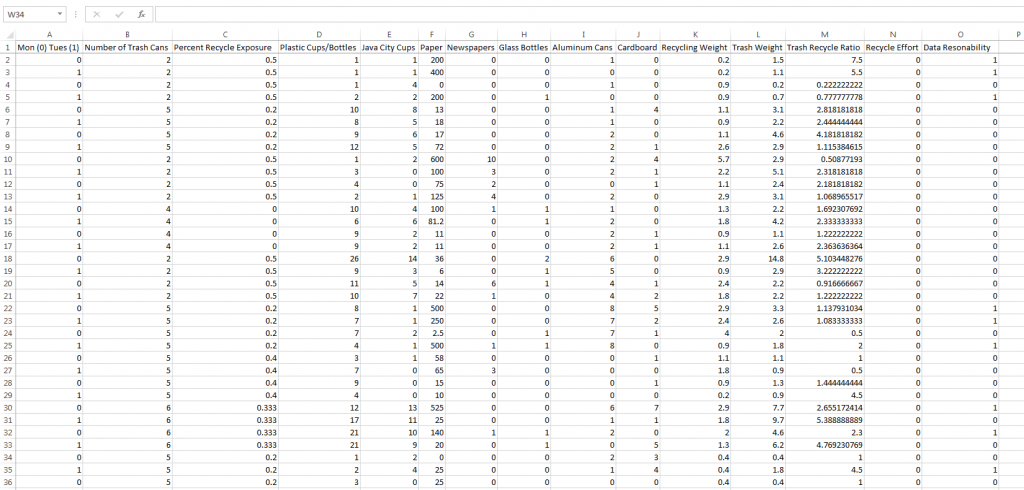
The Data, After Conversion into Long Format and Quantifiable Values
Now that we have all this data in a computer-friendly format, we need to identify and eliminate any extreme outliers present, since they can distort our final model. First we create a regression model with all of the factors included. As part of this, we generate the residuals from the data vs. the fit. For our analysis, we utilized deleted T-residuals. These are less affected by the skew of an outlier compared to regular T-residuals, making it them better indicator. These can be selected to be displayed by Minitab in the same manner that any other residual can be selected. Looking at these residuals, those with values above 4 were removed. A new fit was then created and the process was repeated until no outliers remain.
Satisfying the Assumptions for Regression Analysis
Once the outliers have been eliminated, we need to verify the regression assumptions for our data to ensure that the analysis conducted is valid. We need to satisfy five assumptions:
- The mean value of the errors is zero.
- The variance of the errors is even and consistent (or “homoscedastic”) through the data.
- The data is independent and identically distributed (IID).
- The errors are normally distributed.
- There is negligible variance in the predictor values.
For our third assumption, we know that the data points should be IID, because each area’s daily trash collection should have no effect on that of other areas or the next day’s collection. We have no reason to suspect otherwise. The fifth assumption is also believed to have been met, as we have no reason to suspect that there is variance in the predictor value. This means that only three of the five assumptions still need to be checked.
Our first and second assumptions can be checked simply by plotting the deleted T-residuals against the individual factors, as well as the fits and visually inspecting them.
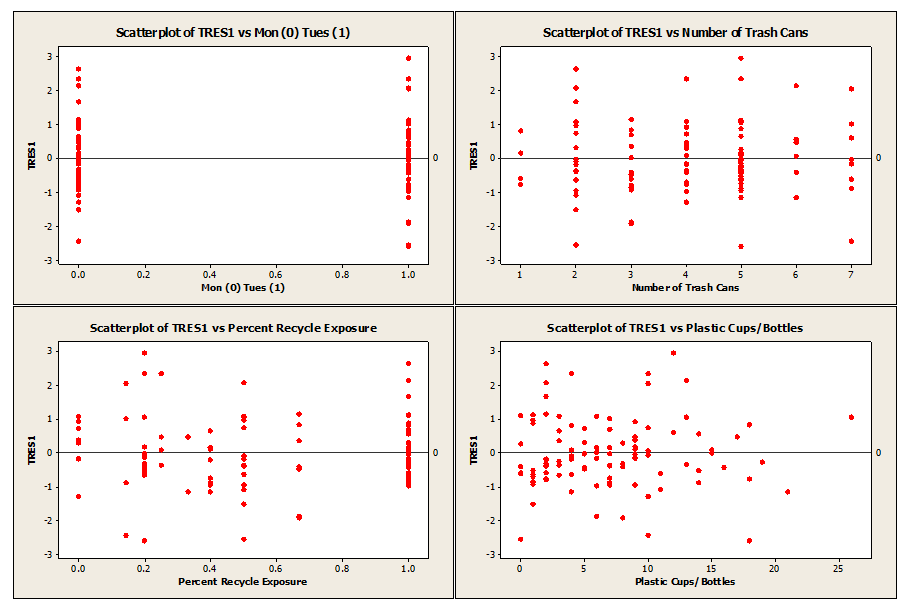
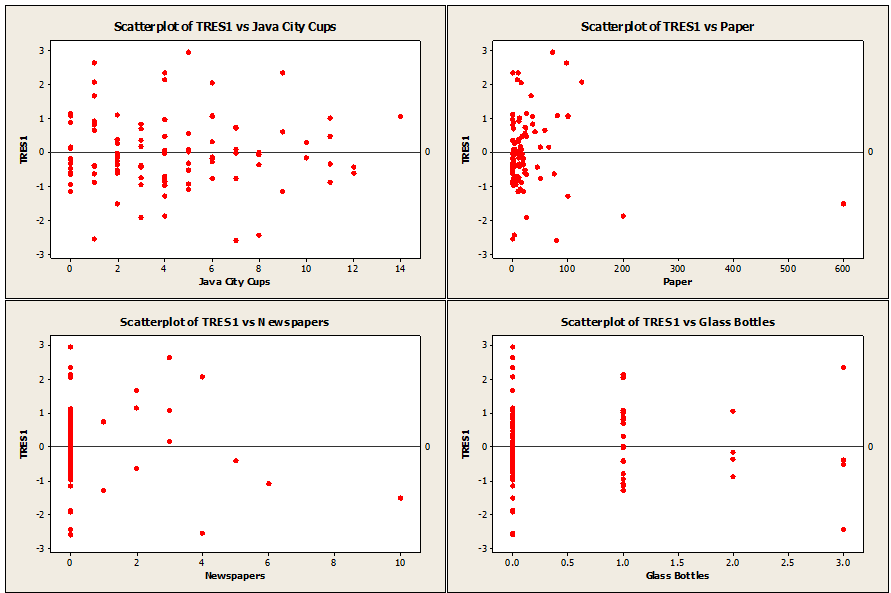
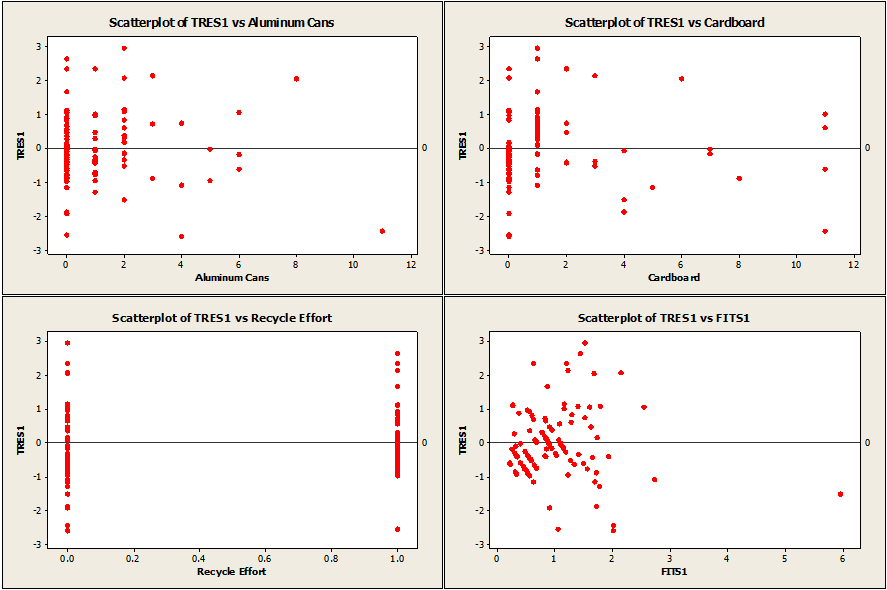
 Plots used to verify regression assumptions.
Plots used to verify regression assumptions.
When looking over the scatter plots, it looks like these two assumptions are met. Checking the fourth assumption is just as easy. All that needs to be done is to run a normality test on the deleted T-residuals.
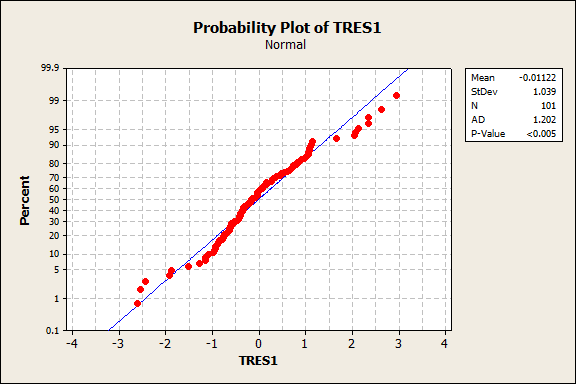
Normality plot of deleted T-residuals
It appears that our residuals are not normally distributed, as seen by the p-value of our test. This is problematic, as it means any analysis we would conduct would be invalid. Fortunately, all is not lost: we can perform a Box-Cox analysis on our results. This will tell us is if the response variable needs to be raised by a power.
![]()
Box-Cox analysis of the data
The results of this analysis indicate that the response variable should be raised by a constant of 0.75. A new model and residuals can be generated from this modified response variable and the assumptions can be checked.
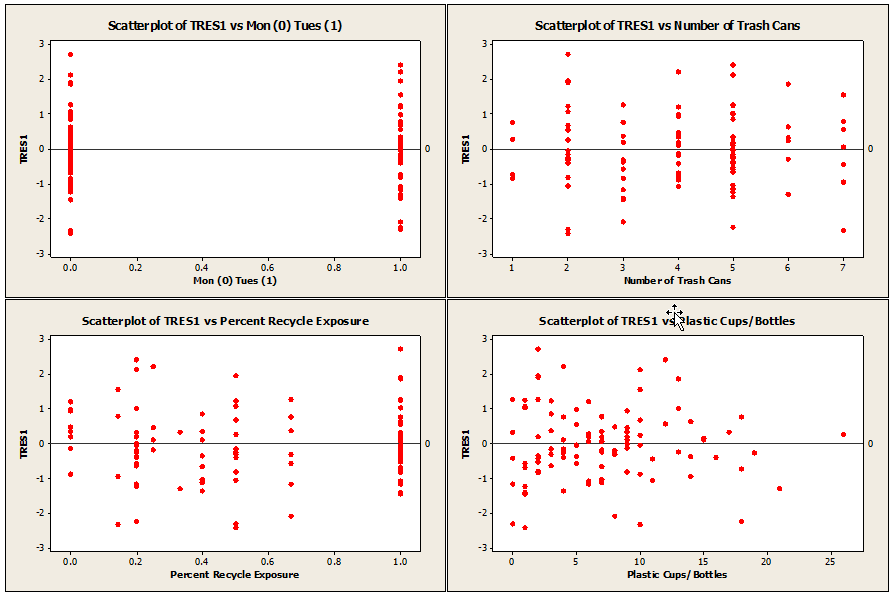
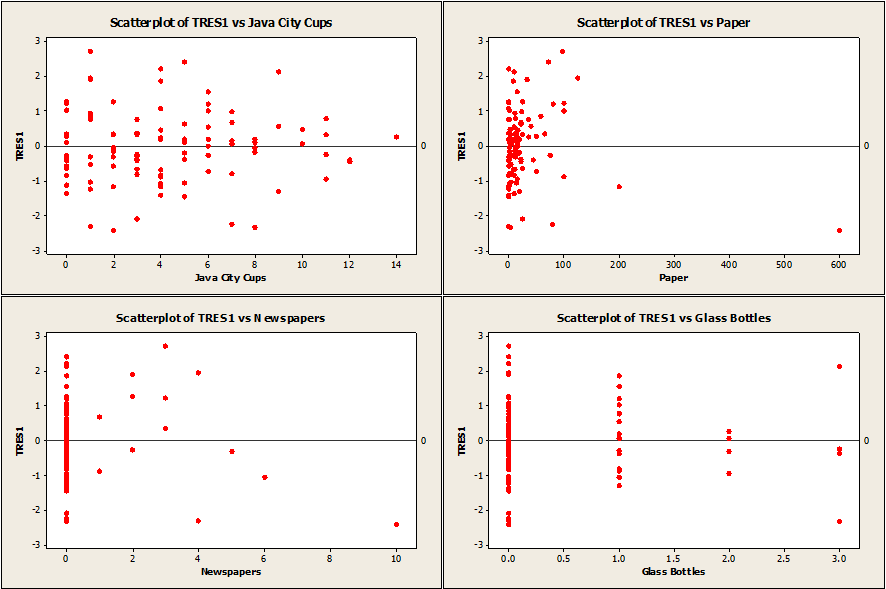
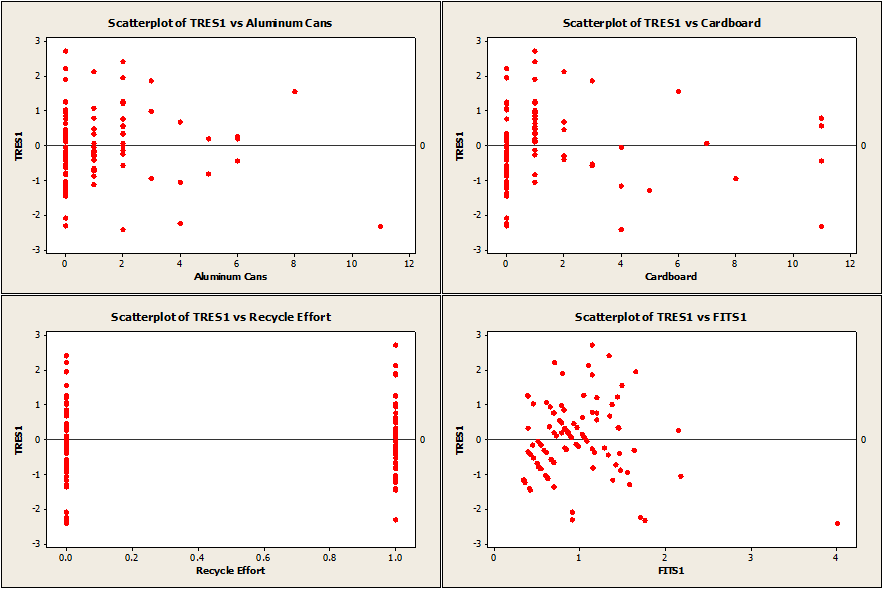 New plots used in order to verify regression assumptions for revised model.
New plots used in order to verify regression assumptions for revised model.
The residuals again appear to be homoscedastic and centered about zero.
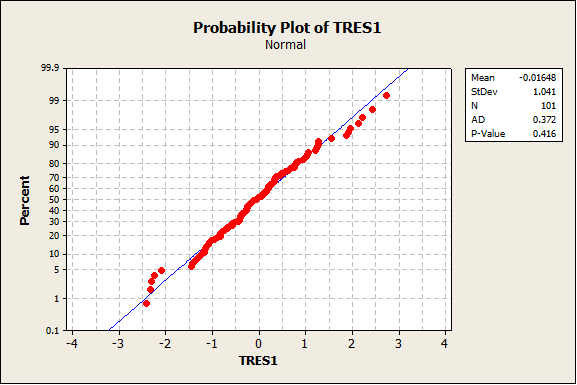
Normality plot on deleted T-residuals
The residuals now are normally distributed. Our data is now prepped and ready for analysis!
The second part of this post will detail the regression analysis.
About the Guest Blogger
Peter Olejnik is a graduate student at the Rose-Hulman Institute of Technology in Terre Haute, Indiana. He holds a bachelor’s degree in mechanical engineering and his professional interests include controls engineering and data analysis.