



In April 2017, overbooking of flight seats hit the headlines when a United Airlines customer was dragged off a flight. A TED talk by Nina Klietsch gives a good, but simplistic explanation of why overbooking is so attractive to airlines.
Overbooking is not new to the airlines; these strategies were officially sanctioned by The American Civil Aeronautics Board in 1965, and since that time complex statistical models have been researched and developed to set the ticket pricing and overbooking strategies to deliver maximum revenue to the airlines.
In this blog, I would like to look at one aspect of this: the probability of a no-show. In Klietsch’s talk, she assumed that the probability of a no-show (a customer not turning up for a flight) is identical for all customers. In reality, this is not true—factors such as time of day, price, time since booking, and whether a traveler is alone or in a group will impact the probability of a no show.
- Credit scores: What is the probability of default?
- Marketing offers: What are the chances you'll buy a product based on a specific offer?
- Quality: What is the probability of a part failing?
- Human resources: What is the sickness absence rate likely to be?
In all cases, your outcome (the event you are predicting) is discrete and can be split into two separate groups; for example, purchase/no purchase, pass/fail, or show/no show. Using the characteristics of your customers or parts as predictors you can use this modeling technique to predict the outcome.
 Let’s look at an example. I was unable to find any airline data, so I am illustrating this with one of our Minitab sample data sets, Cerealpurchase.mtw.
Let’s look at an example. I was unable to find any airline data, so I am illustrating this with one of our Minitab sample data sets, Cerealpurchase.mtw.
In this example, a food company surveys consumers to measure the effectiveness of their television ad in getting viewers to buy their cereal. The Bought column has the value 1 if the respondent purchased the cereal, and the value 0 if not. In addition to asking if respondents have seen the ad, the survey also gathers data on the household income and the number of children, which the company also believes might influence the purchase of this cereal.
Using Stat > Regression > Binary Logistic Regression, I entered the details of the response I wanted to predict, Bought, and the value in the Response Event which indicated a purchase. I then entered the Continuous predictor, Income and the Categorical predictors Children and ViewAd. My completed dialog box looks like this:
After pressing OK, Minitab performs the analysis and displays the results in the Session window. From this table at the top of the output I can see that the researchers surveyed a sample of 71 customers, of which 22 purchased the cereal.

With Logistic regression, the output features a Deviance Table instead of an Analysis of Variance Table. The calculations and test statistics used with this type of data are different, but we still use the P-value on the far right to determine which factors have an effect on our response.
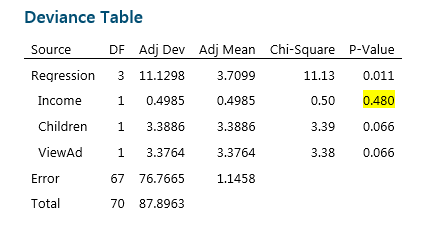
As we would when using other regression methods, we are going to reduce the model by eliminating non-significant terms one at a time. In this case, as highlighted above, Income is not significant. We can simply press Ctrl-E to recall the last dialog box, remove the Income term from the model, and rerun the analysis. Minitab returns the following results:
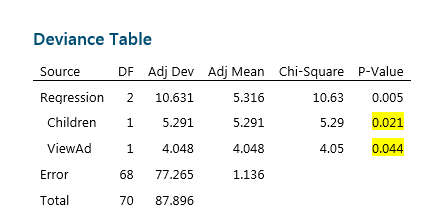
After removing Income, we can see that both Children and ViewAd are significant at the 0.05 significance level. This could be good news for the Marketing Department, as it clearly indicates that viewing the ad did influence the decision to buy. However from this table it is not possible to see if this effect is positive or negative.
To understand this, we need to look at another part of the output. In Binary Logistic Regression, we are trying to estimate the probability of an event. To do this we use the Odds Ratio, which compares the odds of two events by dividing the odds of success under condition A by the odds of success under condition B.
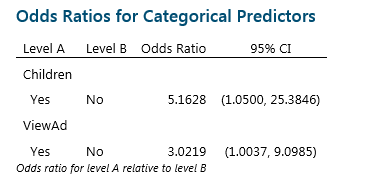
In this example, the Odds Ratio for Children is telling us that respondents who reported they do have children are 5.1628 times more likely to purchase the cereal than those who did not report having children. The good news for the Marketing Department is that customers who viewed the ad were 3.0219 times more likely to purchase the cereal. If the Odds Ratio was less than 1, we would conclude that seeing the advert reduces sales!
 The other way to look at these results is to calculate the probability of purchase and analyse this.
The other way to look at these results is to calculate the probability of purchase and analyse this.
It is easy to calculate the probability of a sale by clicking on the Storage button in the Binary Logistic Regression dialog box and checking the box labeled Fits (event probabilities). This will store the probability of purchase in the worksheet.
Using the fits data, we can produce a table summarizing the Probability of Purchase for all the combinations of Children and ViewAd, as follows:
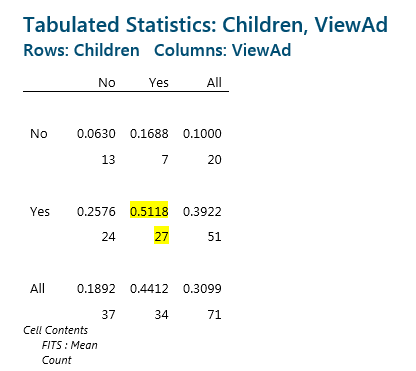
In the rows we have the Children indicator, and in the columns we have the ViewAd indicator. In each cell the top number is the probability of cereal purchase, and the bottom number is the count of customers observed in each of the groups.
Based on this table, customers with children who have seen the ad have a 51% chance of purchase, whereas customers without children who have not seen the ad have a 6% chance of purchase.
Now let's bring this back to our airline example. Using the information about their customers' demographics and flight preferences, an airline can use binary logistic regression to estimate the probabilities of a “no-show” for a whole plane and then determine by how much they should overbook seats. Of course, no model is perfect, and as we saw with United, getting it wrong can have severe consequences.