




De nos jours, le contenu est disponible et accessible partout. Selon une étude Nielsen, les adultes américains passent plus de 11 heures par jour à lire, à écouter et à regarder les médias, ainsi qu'à interagir avec eux. Face à l'afflux de contenu disponible, vous vous demandez peut-être s'il existe une manière quantitative d'examiner de plus près les textes mis à notre disposition.
L'exploration de texte, également appelée exploration de données de texte, désigne le procédé d'extraction d'informations de qualité à partir de textes. L'objectif ultime est d'extraire des mesures numériques d'une variable texte qui peuvent être utilisées dans une modélisation quantitative.
En quoi l'exploration de texte est-elle essentielle ?
L'exploration de texte permet d'identifier de simples tendances ou d'effectuer des analyses de sentiment bien plus complexes. Les statistiques élémentaires peuvent servir à effectuer des analyses simples comme le calcul du nombre de fois qu'un mot est mentionné ou l'extraction du nombre de mots en majuscules.
Une fois que vous avez collecté les statistiques récapitulatives, vous pouvez par exemple utiliser des graphiques à barres pour visualiser les mots les plus fréquemment utilisés, ou des nuages de mots-clés pour les illustrer de manière efficace. Cette technique est particulièrement utile pour identifier les sentiments ou les comportements que génèrent un produit ou un procédé.
Bonne nouvelle ! Découvrez dès maintenant l'exploration de textes grâce au module d'intégration Python dans la dernière version du logiciel d'analyse de données Minitab.

Donner du sens aux textes : exploitation des critiques de vins et fréquence inverse de document
A des fins d'illustration, prenons l'exemple simple de l'analyse de cinq critiques différentes au sujet d'un type spécifique de vin. En effectuant l'analyse dans Minitab à l'aide d'une fonction en Python, vous obtenez un tableau de statistiques récapitulatives très simple à comprendre, similaire à l'exemple suivant :
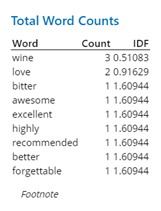
Comme vous pouvez le voir, parmi les cinq critiques, le mot "vin" (wine) est apparu trois fois tandis que le mot "aime" (love) est apparu deux fois et tous les autres mots seulement une fois. Minitab fournit également la fréquence inverse de document (Inverse Document Frequency ou IDF en anglais) pour chaque mot, qui est calculée comme suit :
IDF = ln (N/DF)
où N est égal au nombre d'observations (dans cet exemple, dans chacune des cinq critiques) et DF est égal au nombre de documents dans lesquels un mot donné apparaît.
D'un point de vue mathématique, un mot présent dans toutes les observations aura une IDF de 0. Par conséquent, le mot ayant l'IDF la plus faible est le mot le plus fréquent, tandis qu'un mot présent dans seulement une observation aura l'IDF la plus élevée possible.
Dans cet exemple, il est évident que "vin" présente la plus faible IDF puisqu'il s'agit du mot le plus présent. Selon les statistiques récapitulatives, nous pouvons conclure qu'une majorité des personnes aiment le vin et que les critiques sont dans l'ensemble positives.

Pour ceux d'entre nous qui préfèrent les représentations visuelles, nous pouvons également observer cet échantillon d'analyse sous forme de nuage de mots-clés :
Comme vous pouvez le voir, "vin" (wine) est le plus grand mot, c'est-à-dire le plus couramment utilisé. Un simple coup d'œil à ce nuage de mots-clés vous donne une idée positive de l'ensemble des critiques.
Jugez-en par vous-même
L'exploration de textes est mise en œuvre à l'aide de la nouvelle fonction Python disponible dans Minitab. Ne vous inquiétez pas si vous n'avez jamais utilisé Python auparavant : nous vous fournissons les instructions d'installation et d'utilisation (vous trouverez tout ce dont vous avez besoin de savoir sur l'intégration Python ici). Une fois l'extension correctement installée, vous pouvez poursuivre l'exécution de tâches d'exploration de textes standard dans Minitab.
Vous souhaitez en savoir plus sur les possibilités qu'offre Python dans Minitab ? Consultez notre exemple d'aide ou discutez avec les experts Minitab pour découvrir des méthodes de travail plus avancées comme l'analyse de sentiment, la représentation en sac de mots, et l'analyse sémantique latente !
Découvrez le nouveau module d'intégration Python en action !

