



As we collect more and more observational data from our processes, we might need new tools to provide meaningful insights. You can add modern-day machine learning techniques alongside traditional statistical tools to analyze, improve and control your processes. Let's take a look at an example that starts with binary logistic regression and ends with Classification and Regression Trees (CART®).
Editor's note: An earlier version of this post showing CART in Salford Predictive Modeler was published in March 2018. We have updated it to show CART in the latest version of Minitab.


Finding the Root Cause of Excessive Variation in a
Pulp Bleaching Process
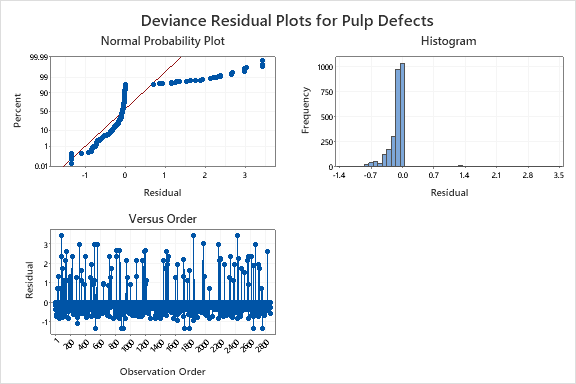
In our example, we know that we are seeing defects in 2.9% of our product. To begin looking at the root cause of this unacceptable percentage of defects in this process, you might begin with a Binary Logistic Regression in Minitab where the response variable is whether an observation was defective or not. Unfortunately, for this data, the crazy patterns in the residual plots below indicate that the binary logistic regression model might not be adequate.
The CART Approach
CART is a decision tree algorithm that works by creating a set of yes/no rules that split the response (Y) variable into partitions based on the predictor (X) settings. Using the CART feature in Minitab, I see that one of my predictor variables – Discharge pH – is a large contributor to a defect.

If discharge pH <= 7.739, then the estimated probability of a defect is relatively high (17.7%). If discharge pH > 7.739, then very few defects occur.
Further Reading:

The Minitab graph below explains why this rule works. The CART model finds the variable and setting that best separates the Response = Pass from the Response = Fail group. Here, that variable and setting is discharge pH at 7.739.

I can continue growing the CART tree to eventually find more combinations of settings that lead to defects in this process. Once I’ve narrowed the problem down to the vital few X’s, I can put controls in place to reduce the chance of defects. In this case, the full CART Classification model identifies some specific combinations of discharge pH and production rate that lead to a disproportionate number of defects as shown in the graph below.

Ready to see for yourself?
