



절차를 통해서 점점 더 많은 관찰 데이터를 수집함에 따라, 의미 있는 통찰력을 제공할 수 있는 새로운 도구가 필요할 수 있습니다. 전통적인 통계 도구에 현대적인 기계 학습 기법을 추가하여 절차를 분석하고 개선하며 관리할 수 있습니다. 이항 로지스틱 회귀 분석으로 시작하여 CART®(Classification and Regression Trees)로 종료되는 예시를 살펴보겠습니다.
 펄프 표백 공정에서 과도한 편차가 발생하는 근본 원인 찾기
펄프 표백 공정에서 과도한 편차가 발생하는 근본 원인 찾기
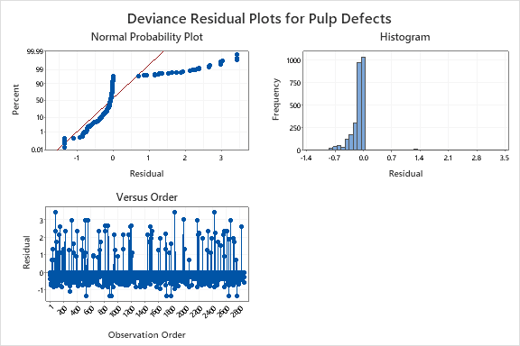
이 예시에서, 결함이 제품의 2.9%에서 관찰되는 것으로 파악되었습니다. 해당 공정에서 허용되지 않는 이러한 결함 백분율의 근본 원인을 살펴보는 첫 단계로서, Minitab의 이항 로직스틱 회귀 분석을 시작할 수 있으며 이때 반응 변수는 관측치의 결함 여부입니다. 안타깝게도, 이 데이터의 경우 아래 잔차 그림의 기이한 패턴에서 이항 로지스틱 회귀 분석 모델이 적절하지 않은 것으로 나타납니다.

CART 접근법
CART는 예측 변수(X) 설정에 따라 반응(Y) 변수를 분할하는 예/아니요 규칙 집합을 생성하여 구동하는 의사 결정 트리 알고리즘입니다. Minitab의 CART 기능을 사용했을 때, 예측 변수 중 하나인 배출 pH (Discharge pH) 가 결함에 대한 큰 기여요인으로 확인됩니다.

배출 pH <= 7.739일 때, 추정 결함 확률은 비교적 높습니다(17.7%). 배출 pH > 7.739일 때, 결함은 매우 드물게 나타납니다.
추가 자료:
아래 Minitab 그래프에서 이 규칙이 효과가 있는 이유가 설명됩니다. CART 모델은 반응 = 불합격 그룹으로부터 반응 = 합격을 가장 잘 구분하는 변수와 설정을 찾습니다. 여기에서, 해당하는 변수와 설정은 7.739의 배출 pH입니다.

이 공정의 결함으로 이어지는 설정의 조합을 최종적으로 찾기 위해 계속해서 CART 트리를 키울 수 있습니다. 문제를 중요한몇 개의 X로 좁혔다면, 관리 방법을 배치하여 결함 가능성을 줄일 수 있습니다. 이 사례에서는 아래 그래프에서 제시된 바와 같이 전체 CART 분류 모델을 통해 불균형적인 결함 수로 이어지는 배출 pH와 생산속도의 몇 가지 조합이 식별됩니다.

직접 경험할 준비가 되셨나요?
